
儘管市面上已經生產了許多大容量的硬碟,但仍然有許多客戶需要節省容量,實現 1 到更多容量的目標。有很多節省容量的方法,市場上最常聽到的是重複資料刪除(Data Deduplication)。今天我們來討論一下它的優點和缺點,以及每個品牌的儲存如何節省容量。
什麼是重複資料刪除(Data Deduplication)?
重複資料刪除是一個過程,它可以消除資料的多餘副本,並顯著減少儲存容量需求。
重複資料刪除可以作為一個內聯過程運行,當資料被寫入儲存系統時,可以消除重複的資料,也可以作為後台過程運行,以在資料寫入磁碟後消除重複的資料。
重複資料刪除操作的性能開銷非常小,因為它運行在一個專用的效能域中,該域與用戶端的讀寫域分離。它在幕後運行,不論運行的是什麼應用程式或資料如何被訪問(在 NAS 或 SAN 中),都不受影響。
重複資料刪除節省的容量在資料移動時得以保持,當資料被複製到災難恢復站點時,當資料被備份到保險庫時,或者當資料在本地、混合雲、或公共雲之間移動時。
為何需要重複資料刪除
重複資料刪除有助於減少與重複資料相關的成本,這對儲存管理員非常重要。大型數據集通常包含大量的重複資料,這會增加儲存資料的成本。例如:
- 用戶文件共享可能包含相同或相似文件的多個副本。
- 虛擬化虛擬機可能幾乎相同。
- 備份快照可能從一天到另一天有較小的差異。
通過重複資料刪除,您可以減少這些冗余資料的儲存需求,節省儲存成本。節省的容量取決於數據集或卷上的工作負載。具有高度重複性的數據集可能實現高達 95% 的優化率,或者儲存利用率減少 20 倍。此外,它還可以“提高寫入性能”和“節省網絡帶寬”。
哪些環境需要這項技術?
重複資料刪除是用來尋找相對較大範圍內的大型重複資料塊,一般而言,這些重複資料塊的大小超過 1KB。這項技術廣泛應用於網絡硬碟、電子郵件、磁碟備份媒體設備等領域。
無論工作負載類型如何,這都是有用的。最大的好處在於虛擬環境,特別是在使用多個虛擬機器進行測試/開發和應用部署的情況下。
虛擬桌面基礎設施(VDI)也是一個非常適合進行去重的候選方案,因為桌面之間的重複資料非常高。
一些關聯式數據庫,如 Oracle 和 SQL,並不會從去重中受益太多,因為它們通常為每個數據庫記錄設有唯一鍵,這會阻止去重引擎將其識別為重複項。
優勢和挑戰
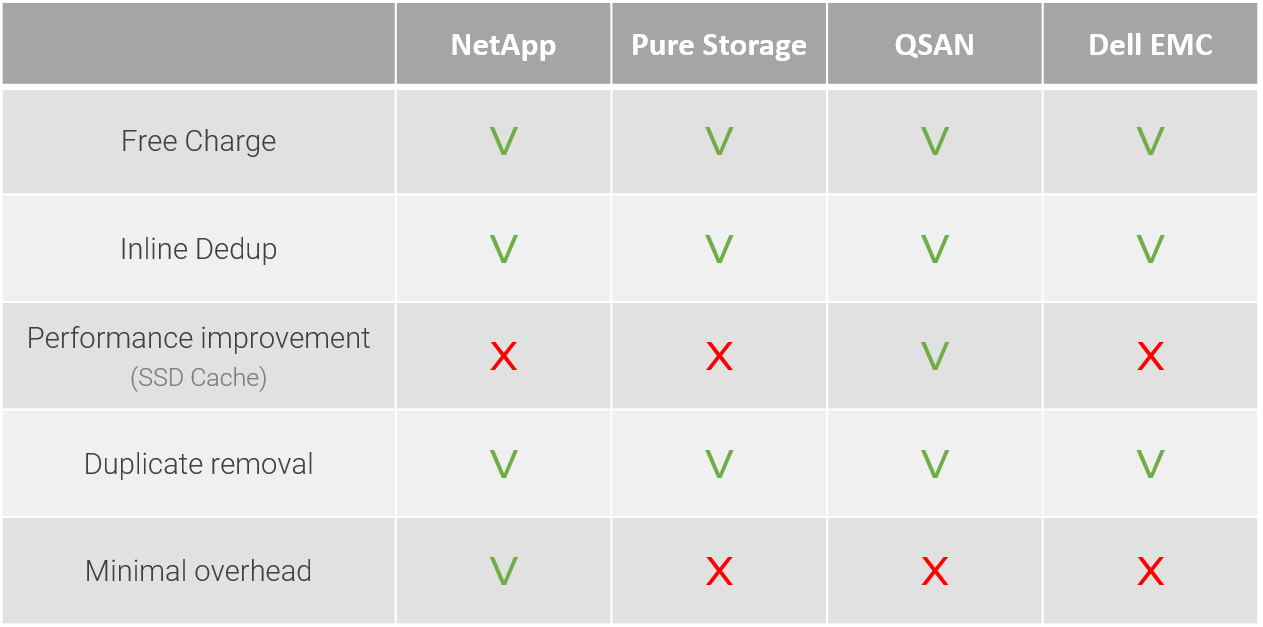
以不妥協的成本效益為目標(全閃存對比混合式)
觀察上面的對比表,不同供應商重複資料刪除的方法可能各不相同,不僅節省空間,還可以在啟用 SSD 緩存的情況下加速性能,這是一個新的趨勢,將來可能會成為必需品,特別是在備份或傳輸資料時,即使去重率很高,也能幫助節省時間。此外,某些品牌在啟用去重的情況下,採用混合設計(使用 SSD 緩存)比全閃存設計要經濟得多,使您在較低預算下實現高性能和低延遲,並通過去重節省大量儲存容量。
但是,如果您需要高隨機 IOPS 和低延遲,也就是用於儲存 IO 模式,例如大量的 SQL 訪問或 VDI 環境,那麼 NVMe 全閃存將是最佳選擇。在這種情況下嘗試不使用重複資料刪除,每種產品設計都有其獨特的用途。
我們的觀點
根據上述研究,重複資料刪除設計可以優化讀性能,對寫性能的影響很小,並提供容量節省的優勢。在以有限預算購買儲存之前,選擇最適合您環境的儲存方案非常重要。儘管當前硬碟容量越來越大,但人們總是希望最大程度地利用資源。市場上還有其他技術可以消除在重建 RAID 過程中的風險擔憂,例如 RAID2.0、快速重建等,這些技術可能有助於在使用更大容量硬碟時減少重建時間。


